binder 是跨进程间的通信,那就是说有本地和远程之说,通过前面几篇也知道 Bp 需要发请求到 Bn 端。但是写过网络通信程序的都知道,远程不一定“靠谱”,就是说可能某些时候远程服务器挂了。所以一般网络通信程序会弄一个心跳的机制,就是每隔一段时间向服务发一些东西,看服务是否还有响应。同理的还有看门狗,如果不定时去“喂狗”(证明程序还活着),机器就会重启之类的。所以 binder 通信也存在这个问题,不过同样也是 android 帮我们弄好框架了。
照例先把相关源码位置啰嗦一下(4.4):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
| frameworks/base/core/android/os/IBinder.java frameworks/base/core/android/os/Binder.java frameworks/base/core/java/android/app/LoadedApk.java frameworks/base/core/jni/android_util_Binder.cpp frameworks/native/cmds/servicemanager/binder.c frameworks/native/cmds/servicemanager/binder.h frameworks/native/cmds/servicemanager/service_manager.c frameworks/native/include/binder/Binder.h frameworks/native/include/binder/BpBinder.h frameworks/native/include/binder/IPCThreadState.h frameworks/native/include/binder/ProcessState.h frameworks/native/libs/binder/IInterface.cpp frameworks/native/libs/binder/Binder.cpp frameworks/native/libs/binder/BpBinder.cpp frameworks/native/libs/binder/IPCThreadState.cpp frameworks/native/libs/binder/ProcessState.cpp frameworks/native/libs/binder/Parcel.cpp kernel/drivers/staging/android/binder.h kernel/drivers/staging/android/binder.c
|
native 层的接口
binder 的东西是 native,java 层挂马甲的,所以先说 native 层的。在 libbinder 中的 IBinder.h 中有一个函数和一个接口类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40
| class DeathRecipient : public virtual RefBase { public: virtual void binderDied(const wp<IBinder>& who) = 0; }; virtual status_t linkToDeath(const sp<DeathRecipient>& recipient, void* cookie = NULL, uint32_t flags = 0) = 0;
|
注释很长,意思就是 linkToDeath 可以允许你注册一个回调接口 DeathRecipient 到 Bp。然后当 Bp 对应的 Bn 挂掉了,DeathRecipient 中的 binderDied 会被调用,然后你可以根据你的业务情况做一些处理。那个 binderDied 的参数就是 Bp 对象自己(看后面的代码)。
注意了,虽然 linkToDeath 是 IBinder 的接口,但是只允许在 Bp 端注册。下面的代码能看得出。而且你想想看,这个东西是通知服务端(Bn)挂了的,如果你注册在 Bn 端,你都挂了,还能掉回调么。所以 注册死亡通知只有在 Bp 才有效。
然后我们接下去看实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41
| status_t BpBinder::linkToDeath( const sp<DeathRecipient>& recipient, void* cookie, uint32_t flags) { Obituary ob; ob.recipient = recipient; ob.cookie = cookie; ob.flags = flags; LOG_ALWAYS_FATAL_IF(recipient == NULL, "linkToDeath(): recipient must be non-NULL"); { AutoMutex _l(mLock); if (!mObitsSent) { if (!mObituaries) { mObituaries = new Vector<Obituary>; if (!mObituaries) { return NO_MEMORY; } ALOGV("Requesting death notification: %p handle %d\n", this, mHandle); getWeakRefs()->incWeak(this); IPCThreadState* self = IPCThreadState::self(); self->requestDeathNotification(mHandle, this); self->flushCommands(); } ssize_t res = mObituaries->add(ob); return res >= (ssize_t)NO_ERROR ? (status_t)NO_ERROR : res; } } return DEAD_OBJECT; }
|
BpBinder 拿一个 Vector 来保存死亡回调,说明一个 Bp 可以注册多个回调的。然后我们在去看 IPCThreadState 的处理之前,来看下 Binder 里 linkToDeath 的实现:
1 2 3 4 5 6
| status_t BBinder::linkToDeath( const sp<DeathRecipient>& recipient, void* cookie, uint32_t flags) { return INVALID_OPERATION; }
|
果然和前面说的一样,Bn 端的 linkToDeath 是不允许调用的。然后我们可以去 IPCThreadState 来看看 requestDeathNotification 的处理了:
1 2 3 4 5 6 7 8 9 10
| status_t IPCThreadState::requestDeathNotification(int32_t handle, BpBinder* proxy) { mOut.writeInt32(BC_REQUEST_DEATH_NOTIFICATION); mOut.writeInt32((int32_t)handle); mOut.writeInt32((int32_t)proxy); return NO_ERROR; }
|
下面把 BC_REQUEST_DEATH_NOTIFICATION 命令写入要发送的数据包(BC 开头的命令是用户空间往内核空间发送的,忘记的回去看通信篇)。然后把 Bp 的 handle 也写入(Bp 的 handle 值在 kernel 中可能找到 node 的 ref,忘记的回去看对象传递篇)。最后把 Bp 自己对象指针也写入(注意是指针,4字节的地址,看过前面的都应该知道,保存指针能用的只能是本进程而已(Bn 的本地指针是到 Bn 进程才能调用的),所以注册死亡通知只能在 Bp 端注册,所以这里可以保存 Bp 指针)。
然后后面还有个 flushCommands:
1 2 3 4 5 6 7 8 9
| void IPCThreadState::flushCommands() { if (mProcess->mDriverFD <= 0) return; talkWithDriver(false); }
|
Bp 本来要等到 transact(调用 talkWithDriver) 才会真正去对驱动写数据。这个 flushCommands 意思就是马上把命令发出去(很多 I/O 接口都有类似的叫 flush 的函数)。原来就是直接调用了 talkWithDriver 而已(false 不需要返回的)。下面就是到 kernel 的 binder 驱动中去了。我们继续去 kernel 里面去看。
注册死亡通知到 kernel
IPCThreadState 调用的 ioctl 发送的是 BINDER_WRITE_READ 命令,然后不需要返回,那就是只会调用 binder_thread_write 而已,然后我来看看 BC_REQUEST_DEATH_NOTIFICATION 命令的处理:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119
| int binder_thread_write(struct binder_proc *proc, struct binder_thread *thread, void __user *buffer, int size, signed long *consumed) { uint32_t cmd; void __user *ptr = buffer + *consumed; void __user *end = buffer + size; while (ptr < end && thread->return_error == BR_OK) { if (get_user(cmd, (uint32_t __user *)ptr)) return -EFAULT; ptr += sizeof(uint32_t); if (_IOC_NR(cmd) < ARRAY_SIZE(binder_stats.bc)) { binder_stats.bc[_IOC_NR(cmd)]++; proc->stats.bc[_IOC_NR(cmd)]++; thread->stats.bc[_IOC_NR(cmd)]++; } switch (cmd) { ... ... case BC_REQUEST_DEATH_NOTIFICATION: case BC_CLEAR_DEATH_NOTIFICATION: { uint32_t target; void __user *cookie; struct binder_ref *ref; struct binder_ref_death *death; if (get_user(target, (uint32_t __user *)ptr)) return -EFAULT; ptr += sizeof(uint32_t); if (get_user(cookie, (void __user * __user *)ptr)) return -EFAULT; ptr += sizeof(void *); ref = binder_get_ref(proc, target); if (ref == NULL) { binder_user_error("binder: %d:%d %s " "invalid ref %d\n", proc->pid, thread->pid, cmd == BC_REQUEST_DEATH_NOTIFICATION ? "BC_REQUEST_DEATH_NOTIFICATION" : "BC_CLEAR_DEATH_NOTIFICATION", target); break; } binder_debug(BINDER_DEBUG_DEATH_NOTIFICATION, "binder: %d:%d %s %p ref %d desc %d s %d w %d for node %d\n", proc->pid, thread->pid, cmd == BC_REQUEST_DEATH_NOTIFICATION ? "BC_REQUEST_DEATH_NOTIFICATION" : "BC_CLEAR_DEATH_NOTIFICATION", cookie, ref->debug_id, ref->desc, ref->strong, ref->weak, ref->node->debug_id); if (cmd == BC_REQUEST_DEATH_NOTIFICATION) { if (ref->death) { binder_user_error("binder: %d:%" "d BC_REQUEST_DEATH_NOTI" "FICATION death notific" "ation already set\n", proc->pid, thread->pid); break; } death = kzalloc(sizeof(*death), GFP_KERNEL); if (death == NULL) { thread->return_error = BR_ERROR; binder_debug(BINDER_DEBUG_FAILED_TRANSACTION, "binder: %d:%d " "BC_REQUEST_DEATH_NOTIFICATION failed\n", proc->pid, thread->pid); break; } binder_stats_created(BINDER_STAT_DEATH); INIT_LIST_HEAD(&death->work.entry); death->cookie = cookie; ref->death = death; if (ref->node->proc == NULL) { ref->death->work.type = BINDER_WORK_DEAD_BINDER; printk(KERN_INFO "binder: %d:%d in binder_thread_write BC_REQUEST_DEATH or CLEAR: 0x%08x \n", proc->pid, thread->pid, cmd); if (thread->looper & (BINDER_LOOPER_STATE_REGISTERED | BINDER_LOOPER_STATE_ENTERED)) { list_add_tail(&ref->death->work.entry, &thread->todo); } else { list_add_tail(&ref->death->work.entry, &proc->todo); wake_up_interruptible(&proc->wait); } } } else { ... ... } } break; ... ... default: printk(KERN_ERR "binder: %d:%d unknown command %d\n", proc->pid, thread->pid, cmd); return -EINVAL; } *consumed = ptr - buffer; } return 0; }
|
然后先来看看相关的数据结构先:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38
| struct binder_work { struct list_head entry; enum { BINDER_WORK_TRANSACTION = 1, BINDER_WORK_TRANSACTION_COMPLETE, BINDER_WORK_NODE, BINDER_WORK_DEAD_BINDER, BINDER_WORK_DEAD_BINDER_AND_CLEAR, BINDER_WORK_CLEAR_DEATH_NOTIFICATION, } type; }; struct binder_ref_death { struct binder_work work; void __user *cookie; }; struct binder_ref { int debug_id; struct rb_node rb_node_desc; struct rb_node rb_node_node; struct hlist_node node_entry; struct binder_proc *proc; struct binder_node *node; uint32_t desc; int strong; int weak; struct binder_ref_death *death; };
|
数据结构不算复杂。然后这个注册过程就算结束了。当 Bp 注册了死亡回调后,native 的 Bp 会把 DeathRecipient 保存到自己的一个结构中,然后发命令给 kernel,在 kernel 中的 Bp 对应的 ref 中也保存到了一个结构中。就是说这个回调最终是注册到 kernel 里面的。
触发死亡通知
上面说了注册最终是注册到 kernel 里面的,那触发也应该是由 kernel 来触发的。实际就是这样的。那我们来看下是怎么触发死亡通知的。binder 驱动有个关闭(释放)操作的函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
| static const struct file_operations binder_fops = { .owner = THIS_MODULE, .poll = binder_poll, .unlocked_ioctl = binder_ioctl, .mmap = binder_mmap, .open = binder_open, .flush = binder_flush, .release = binder_release, }; static int binder_release(struct inode *nodp, struct file *filp) { struct binder_proc *proc = filp->private_data; debugfs_remove(proc->debugfs_entry); binder_defer_work(proc, BINDER_DEFERRED_RELEASE); return 0; }
|
我们来看最后那个函数 binder_defer_work:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42
| static HLIST_HEAD(binder_procs); static HLIST_HEAD(binder_deferred_list); static HLIST_HEAD(binder_dead_nodes); static struct workqueue_struct *binder_deferred_workqueue; static int __init binder_init(void) { int ret; binder_deferred_workqueue = create_singlethread_workqueue("binder"); if (!binder_deferred_workqueue) return -ENOMEM; ... ... return ret; } static DECLARE_WORK(binder_deferred_work, binder_deferred_func); static void binder_defer_work(struct binder_proc *proc, enum binder_deferred_state defer) { mutex_lock(&binder_deferred_lock); proc->deferred_work |= defer; if (hlist_unhashed(&proc->deferred_work_node)) { hlist_add_head(&proc->deferred_work_node, &binder_deferred_list); queue_work(binder_deferred_workqueue, &binder_deferred_work); } mutex_unlock(&binder_deferred_lock); }
|
这个函数是设置一个工作队列。注意这里的工作队列是 kernel 提供的机制,不是前面说的 binder 添加的那个工作列队。kernel 提供的 workqueue 是提供一种延迟执行的机制,通常硬件设备需要一定的时间才能执行完指令操作,所以需要这种机制。这里应该是等 binder 设备关闭完成才执行吧(关于 workqueue 可以自己去查一些 kernel 相关的资料)。看这个函数的名字: binder_defer_work,名字都带延迟(defer 就是延迟的意思)。反正这里就理解为 binder 设备关闭之后,会执行工作队列设置的那个函数 binder_deferred_func 就行了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45
| static void binder_deferred_func(struct work_struct *work) { struct binder_proc *proc; struct files_struct *files; int defer; do { mutex_lock(&binder_lock); mutex_lock(&binder_deferred_lock); if (!hlist_empty(&binder_deferred_list)) { proc = hlist_entry(binder_deferred_list.first, struct binder_proc, deferred_work_node); hlist_del_init(&proc->deferred_work_node); defer = proc->deferred_work; proc->deferred_work = 0; } else { proc = NULL; defer = 0; } mutex_unlock(&binder_deferred_lock); files = NULL; if (defer & BINDER_DEFERRED_PUT_FILES) { files = proc->files; if (files) proc->files = NULL; } if (defer & BINDER_DEFERRED_FLUSH) binder_deferred_flush(proc); if (defer & BINDER_DEFERRED_RELEASE) binder_deferred_release(proc); mutex_unlock(&binder_lock); if (files) put_files_struct(files); } while (proc); }
|
我们接下去看 binder_deferred_release:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85
| static void binder_deferred_release(struct binder_proc *proc) { struct hlist_node *pos; struct binder_transaction *t; struct rb_node *n; int threads, nodes, incoming_refs, outgoing_refs, buffers, active_transactions, page_count; BUG_ON(proc->vma); BUG_ON(proc->files); hlist_del(&proc->proc_node); if (binder_context_mgr_node && binder_context_mgr_node->proc == proc) { binder_debug(BINDER_DEBUG_DEAD_BINDER, "binder_release: %d context_mgr_node gone\n", proc->pid); binder_context_mgr_node = NULL; } threads = 0; active_transactions = 0; while ((n = rb_first(&proc->threads))) { struct binder_thread *thread = rb_entry(n, struct binder_thread, rb_node); threads++; active_transactions += binder_free_thread(proc, thread); } nodes = 0; incoming_refs = 0; while ((n = rb_first(&proc->nodes))) { struct binder_node *node = rb_entry(n, struct binder_node, rb_node); nodes++; rb_erase(&node->rb_node, &proc->nodes); list_del_init(&node->work.entry); if (hlist_empty(&node->refs)) { kfree(node); binder_stats_deleted(BINDER_STAT_NODE); } else { struct binder_ref *ref; int death = 0; node->proc = NULL; node->local_strong_refs = 0; node->local_weak_refs = 0; hlist_add_head(&node->dead_node, &binder_dead_nodes); hlist_for_each_entry(ref, pos, &node->refs, node_entry) { incoming_refs++; if (ref->death) { death++; if (list_empty(&ref->death->work.entry)) { ref->death->work.type = BINDER_WORK_DEAD_BINDER; list_add_tail(&ref->death->work.entry, &ref->proc->todo); wake_up_interruptible(&ref->proc->wait); } else BUG(); } } binder_debug(BINDER_DEBUG_DEAD_BINDER, "binder: node %d now dead, " "refs %d, death %d\n", node->debug_id, incoming_refs, death); } } ... ... kfree(proc); }
|
看样子是在释放 Bn 的 kernel 的 proc 时候去检测在 proc 的 node 的 ref 有没有注册死亡通知回调(前面上层发注册命令注册)。如果注册了,就添加一个 work 到 ref 的进程的 todo list,并唤醒它。这个 ref 的进程就是 Bp 了,前面注册也是 Bp 注册的。然后根据前面通信篇说的,这个唤醒的是 binder_thread_read,但是不是所有 Bp 都会阻塞在 read 那的,一般 Bn 才会(不过很多 Bn 也经常当 Bp 的,例如请求别的服务)。如果是普通单纯的 Bp 的要等到下一次 transact 才能有机会收到这个通知。好了,我们继续去 Bp 的 binder_thread_read 里面去看:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100
| static int binder_thread_read(struct binder_proc *proc, struct binder_thread *thread, void __user *buffer, int size, signed long *consumed, int non_block) { void __user *ptr = buffer + *consumed; void __user *end = buffer + size; ... ... while (1) { uint32_t cmd; struct binder_transaction_data tr; struct binder_work *w; struct binder_transaction *t = NULL; if (!list_empty(&thread->todo)) w = list_first_entry(&thread->todo, struct binder_work, entry); else if (!list_empty(&proc->todo) && wait_for_proc_work) w = list_first_entry(&proc->todo, struct binder_work, entry); else { if (ptr - buffer == 4 && !(thread->looper & BINDER_LOOPER_STATE_NEED_RETURN)) goto retry; break; } if (end - ptr < sizeof(tr) + 4) break; switch (w->type) { ... ... case BINDER_WORK_DEAD_BINDER: case BINDER_WORK_DEAD_BINDER_AND_CLEAR: case BINDER_WORK_CLEAR_DEATH_NOTIFICATION: { struct binder_ref_death *death; uint32_t cmd; death = container_of(w, struct binder_ref_death, work); if (w->type == BINDER_WORK_CLEAR_DEATH_NOTIFICATION) cmd = BR_CLEAR_DEATH_NOTIFICATION_DONE; else cmd = BR_DEAD_BINDER; if (put_user(cmd, (uint32_t __user *)ptr)) return -EFAULT; ptr += sizeof(uint32_t); if (put_user(death->cookie, (void * __user *)ptr)) return -EFAULT; ptr += sizeof(void *); binder_debug(BINDER_DEBUG_DEATH_NOTIFICATION, "binder: %d:%d %s %p\n", proc->pid, thread->pid, cmd == BR_DEAD_BINDER ? "BR_DEAD_BINDER" : "BR_CLEAR_DEATH_NOTIFICATION_DONE", death->cookie); if (w->type == BINDER_WORK_CLEAR_DEATH_NOTIFICATION) { list_del(&w->entry); kfree(death); binder_stats_deleted(BINDER_STAT_DEATH); } else list_move(&w->entry, &proc->delivered_death); if (cmd == BR_DEAD_BINDER) goto done; } break; } ... ... } done: *consumed = ptr - buffer; if (proc->requested_threads + proc->ready_threads == 0 && proc->requested_threads_started < proc->max_threads && (thread->looper & (BINDER_LOOPER_STATE_REGISTERED | BINDER_LOOPER_STATE_ENTERED)) ) { proc->requested_threads++; binder_debug(BINDER_DEBUG_THREADS, "binder: %d:%d BR_SPAWN_LOOPER\n", proc->pid, thread->pid); if (put_user(BR_SPAWN_LOOPER, (uint32_t __user *)buffer)) return -EFAULT; } return 0; }
|
根据前面通信篇的分析,这里 kernel 向用户空间发送了一个返回值: BR_DEAD_BINDER,并把之前用户空间注册时候发过来的那个指针原封不动的发了回去。我们现在要去用户空间看下,最终是怎么触发用户空间的回调的。我们发现 IPCThreadState 有处理 BR_DEAD_BINDER 的地方是 executeCommand。这个函数我们看看在哪几个地方会调用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72
| status_t IPCThreadState::getAndExecuteCommand() { status_t result; int32_t cmd; result = talkWithDriver(); if (result >= NO_ERROR) { size_t IN = mIn.dataAvail(); if (IN < sizeof(int32_t)) return result; cmd = mIn.readInt32(); IF_LOG_COMMANDS() { alog << "Processing top-level Command: " << getReturnString(cmd) << endl; } result = executeCommand(cmd); set_sched_policy(mMyThreadId, SP_FOREGROUND); } return result; } status_t IPCThreadState::waitForResponse(Parcel *reply, status_t *acquireResult) { int32_t cmd; int32_t err; while (1) { if ((err=talkWithDriver()) < NO_ERROR) break; err = mIn.errorCheck(); if (err < NO_ERROR) break; if (mIn.dataAvail() == 0) continue; cmd = mIn.readInt32(); IF_LOG_COMMANDS() { alog << "Processing waitForResponse Command: " << getReturnString(cmd) << endl; } switch (cmd) { ... ... default: err = executeCommand(cmd); if (err != NO_ERROR) goto finish; break; } } finish: if (err != NO_ERROR) { if (acquireResult) *acquireResult = err; if (reply) reply->setError(err); mLastError = err; } return err; }
|
这个2个函数,一个 getAndExecuteCommand 是当 Bn 的服务循环阻塞等待请求的时候调用的;一个 waitForResponse 是 Bp 发请求给 Bn,等待服务返回的时候调用的。正好对应上面说的2种情况,一个是服务中当别服务的 Bp,一个是普通应用的 Bp。
然后我们继续看 executeCommand:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36
| status_t IPCThreadState::executeCommand(int32_t cmd) { BBinder* obj; RefBase::weakref_type* refs; status_t result = NO_ERROR; switch (cmd) { ... ... case BR_DEAD_BINDER: { BpBinder *proxy = (BpBinder*)mIn.readInt32(); proxy->sendObituary(); mOut.writeInt32(BC_DEAD_BINDER_DONE); mOut.writeInt32((int32_t)proxy); } break; ... ... default: printf("*** BAD COMMAND %d received from Binder driver\n", cmd); result = UNKNOWN_ERROR; break; } if (result != NO_ERROR) { mLastError = result; } return result; }
|
前面 Bp 注册把自己的指针传到注册里面去,这里又取出,调用自己的函数。所以前面说注册只能在 Bp 里面注册,要是在 Bn 里注册,这里怎么调用 Bp 的函数。我们去看下 Bp 的 sendObituary 函数(名字真形象,发送仆告):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39
| void BpBinder::sendObituary() { ALOGV("Sending obituary for proxy %p handle %d, mObitsSent=%s\n", this, mHandle, mObitsSent ? "true" : "false"); mAlive = 0; if (mObitsSent) return; mLock.lock(); Vector<Obituary>* obits = mObituaries; if(obits != NULL) { ALOGV("Clearing sent death notification: %p handle %d\n", this, mHandle); IPCThreadState* self = IPCThreadState::self(); self->clearDeathNotification(mHandle, this); self->flushCommands(); mObituaries = NULL; } mObitsSent = 1; mLock.unlock(); ALOGV("Reporting death of proxy %p for %d recipients\n", this, obits ? obits->size() : 0); if (obits != NULL) { const size_t N = obits->size(); for (size_t i=0; i<N; i++) { reportOneDeath(obits->itemAt(i)); } delete obits; } }
|
看样子,这个死亡通知会如果被触发过一次就会被自动清理掉。想想看,确实,发送过一次,说明那个服务已经挂了,当然不会死二次。那我们先去看看这个回调怎么清理掉的:
1 2 3 4 5 6 7 8
| status_t IPCThreadState::clearDeathNotification(int32_t handle, BpBinder* proxy) { mOut.writeInt32(BC_CLEAR_DEATH_NOTIFICATION); mOut.writeInt32((int32_t)handle); mOut.writeInt32((int32_t)proxy); return NO_ERROR; }
|
简单明了的处理。对 kernel 发了一个 BC_CLEAR_DEATH_NOTIFICATION 命令,然后后面一个 flushCommands,马上调用 ioctl 能马上发送到 kernel。这个处理在 binder_thread_write 里面,还记得前面发注册命令 BC_REQUEST_DEATH_NOTIFICATION 时候那个分支也有 BC_CLEAR_DEATH_NOTIFICATION 的么,现在可以来看一下了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49
| if (cmd == BC_REQUEST_DEATH_NOTIFICATION) { ... ... } else { if (ref->death == NULL) { binder_user_error("binder: %d:%" "d BC_CLEAR_DEATH_NOTIFI" "CATION death notificat" "ion not active\n", proc->pid, thread->pid); break; } death = ref->death; if (death->cookie != cookie) { binder_user_error("binder: %d:%" "d BC_CLEAR_DEATH_NOTIFI" "CATION death notificat" "ion cookie mismatch " "%p != %p\n", proc->pid, thread->pid, death->cookie, cookie); break; } ref->death = NULL; if (list_empty(&death->work.entry)) { death->work.type = BINDER_WORK_CLEAR_DEATH_NOTIFICATION; if (thread->looper & (BINDER_LOOPER_STATE_REGISTERED | BINDER_LOOPER_STATE_ENTERED)) { list_add_tail(&death->work.entry, &thread->todo); } else { list_add_tail(&death->work.entry, &proc->todo); wake_up_interruptible(&proc->wait); } } else { BUG_ON(death->work.type != BINDER_WORK_DEAD_BINDER); death->work.type = BINDER_WORK_DEAD_BINDER_AND_CLEAR; } }
|
binder_thead_write 里面的清理只是把 ref 的回调设置成 NULL 了。然后要靠下一次 binder_thread_read 继续清理。注意这里是要等到下一次 ioctl 才能有 binder_thread_read 的,因为前面用 flushCommads 调用 talkWithDeriver 是不带返回值的,所以这次不会调用 binder_thread_read 的。那个我们先提前来看下吧(BINDER_WORK_CLEAR_DEATH_NOTIFICATION 前面也有看到,都是走一个分支的):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40
| case BINDER_WORK_DEAD_BINDER: case BINDER_WORK_DEAD_BINDER_AND_CLEAR: case BINDER_WORK_CLEAR_DEATH_NOTIFICATION: { struct binder_ref_death *death; uint32_t cmd; death = container_of(w, struct binder_ref_death, work); if (w->type == BINDER_WORK_CLEAR_DEATH_NOTIFICATION) cmd = BR_CLEAR_DEATH_NOTIFICATION_DONE; else cmd = BR_DEAD_BINDER; if (put_user(cmd, (uint32_t __user *)ptr)) return -EFAULT; ptr += sizeof(uint32_t); if (put_user(death->cookie, (void * __user *)ptr)) return -EFAULT; ptr += sizeof(void *); binder_debug(BINDER_DEBUG_DEATH_NOTIFICATION, "binder: %d:%d %s %p\n", proc->pid, thread->pid, cmd == BR_DEAD_BINDER ? "BR_DEAD_BINDER" : "BR_CLEAR_DEATH_NOTIFICATION_DONE", death->cookie); if (w->type == BINDER_WORK_CLEAR_DEATH_NOTIFICATION) { list_del(&w->entry); kfree(death); binder_stats_deleted(BINDER_STAT_DEATH); } else list_move(&w->entry, &proc->delivered_death); if (cmd == BR_DEAD_BINDER) goto done; } break; }
|
这样之前注册时候申请的资源就差不多释放完了。不过还要继续去用户空间看看 BINDER_WORK_CLEAR_DEATH_NOTIFICATION 的处理:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
| status_t IPCThreadState::executeCommand(int32_t cmd) { BBinder* obj; RefBase::weakref_type* refs; status_t result = NO_ERROR; switch (cmd) { ... ... case BR_CLEAR_DEATH_NOTIFICATION_DONE: { BpBinder *proxy = (BpBinder*)mIn.readInt32(); proxy->getWeakRefs()->decWeak(proxy); } break; ... ... default: printf("*** BAD COMMAND %d received from Binder driver\n", cmd); result = UNKNOWN_ERROR; break; } if (result != NO_ERROR) { mLastError = result; } return result; }
|
死亡通知回调就差不多清理完了。然后我们可以继续来看死亡通知的发送了(搞了半天还没触发回调咧)。我们回到 sendObituary 的后面那部分,循环取 mObituaries 的每一元素,然后调用 reportOneDeath:
1 2 3 4 5 6 7 8 9 10 11 12
| void BpBinder::reportOneDeath(const Obituary& obit) { sp<DeathRecipient> recipient = obit.recipient.promote(); ALOGV("Reporting death to recipient: %p\n", recipient.get()); if (recipient == NULL) return; recipient->binderDied(this); }
|
到这里就算把死亡通知通知到位了。调用了 Bp 注册的回调,然后就是不同的业务不同的处理了。
通知发送完了,但是上面 IPCThreadState 的 BR_DEAD_BINDER 最后还有一个处理:对 kernel 发了一条 BC_DEAD_BINDER_DONE 命令,我们来看看最后的处理吧:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43
| case BC_DEAD_BINDER_DONE: { struct binder_work *w; void __user *cookie; struct binder_ref_death *death = NULL; if (get_user(cookie, (void __user * __user *)ptr)) return -EFAULT; ptr += sizeof(void *); list_for_each_entry(w, &proc->delivered_death, entry) { struct binder_ref_death *tmp_death = container_of(w, struct binder_ref_death, work); if (tmp_death->cookie == cookie) { death = tmp_death; break; } } binder_debug(BINDER_DEBUG_DEAD_BINDER, "binder: %d:%d BC_DEAD_BINDER_DONE %p found %p\n", proc->pid, thread->pid, cookie, death); if (death == NULL) { binder_user_error("binder: %d:%d BC_DEAD" "_BINDER_DONE %p not found\n", proc->pid, thread->pid, cookie); break; } list_del_init(&death->work.entry); if (death->work.type == BINDER_WORK_DEAD_BINDER_AND_CLEAR) { death->work.type = BINDER_WORK_CLEAR_DEATH_NOTIFICATION; if (thread->looper & (BINDER_LOOPER_STATE_REGISTERED | BINDER_LOOPER_STATE_ENTERED)) { list_add_tail(&death->work.entry, &thread->todo); } else { list_add_tail(&death->work.entry, &proc->todo); wake_up_interruptible(&proc->wait); } } } break;
|
我们接着去看 binder_thread_read 里面看看 BINDER_WORK_CLEAR_DEATH_NOTIFICATION 的处理(前面好像有看到过):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38
| case BINDER_WORK_DEAD_BINDER: case BINDER_WORK_DEAD_BINDER_AND_CLEAR: case BINDER_WORK_CLEAR_DEATH_NOTIFICATION: { struct binder_ref_death *death; uint32_t cmd; death = container_of(w, struct binder_ref_death, work); if (w->type == BINDER_WORK_CLEAR_DEATH_NOTIFICATION) cmd = BR_CLEAR_DEATH_NOTIFICATION_DONE; else cmd = BR_DEAD_BINDER; if (put_user(cmd, (uint32_t __user *)ptr)) return -EFAULT; ptr += sizeof(uint32_t); if (put_user(death->cookie, (void * __user *)ptr)) return -EFAULT; ptr += sizeof(void *); binder_debug(BINDER_DEBUG_DEATH_NOTIFICATION, "binder: %d:%d %s %p\n", proc->pid, thread->pid, cmd == BR_DEAD_BINDER ? "BR_DEAD_BINDER" : "BR_CLEAR_DEATH_NOTIFICATION_DONE", death->cookie); if (w->type == BINDER_WORK_CLEAR_DEATH_NOTIFICATION) { list_del(&w->entry); kfree(death); binder_stats_deleted(BINDER_STAT_DEATH); } else list_move(&w->entry, &proc->delivered_death); if (cmd == BR_DEAD_BINDER) goto done; } break; }
|
然后接着回去 IPCThreadState 再去看看 BR_CLEAR_DEATH_NOTIFICATION_DONE 的处理:
1 2 3 4 5 6 7
| case BR_CLEAR_DEATH_NOTIFICATION_DONE: { BpBinder *proxy = (BpBinder*)mIn.readInt32(); proxy->getWeakRefs()->decWeak(proxy); } break;
|
到这里处理终于完了。上一张图吧:
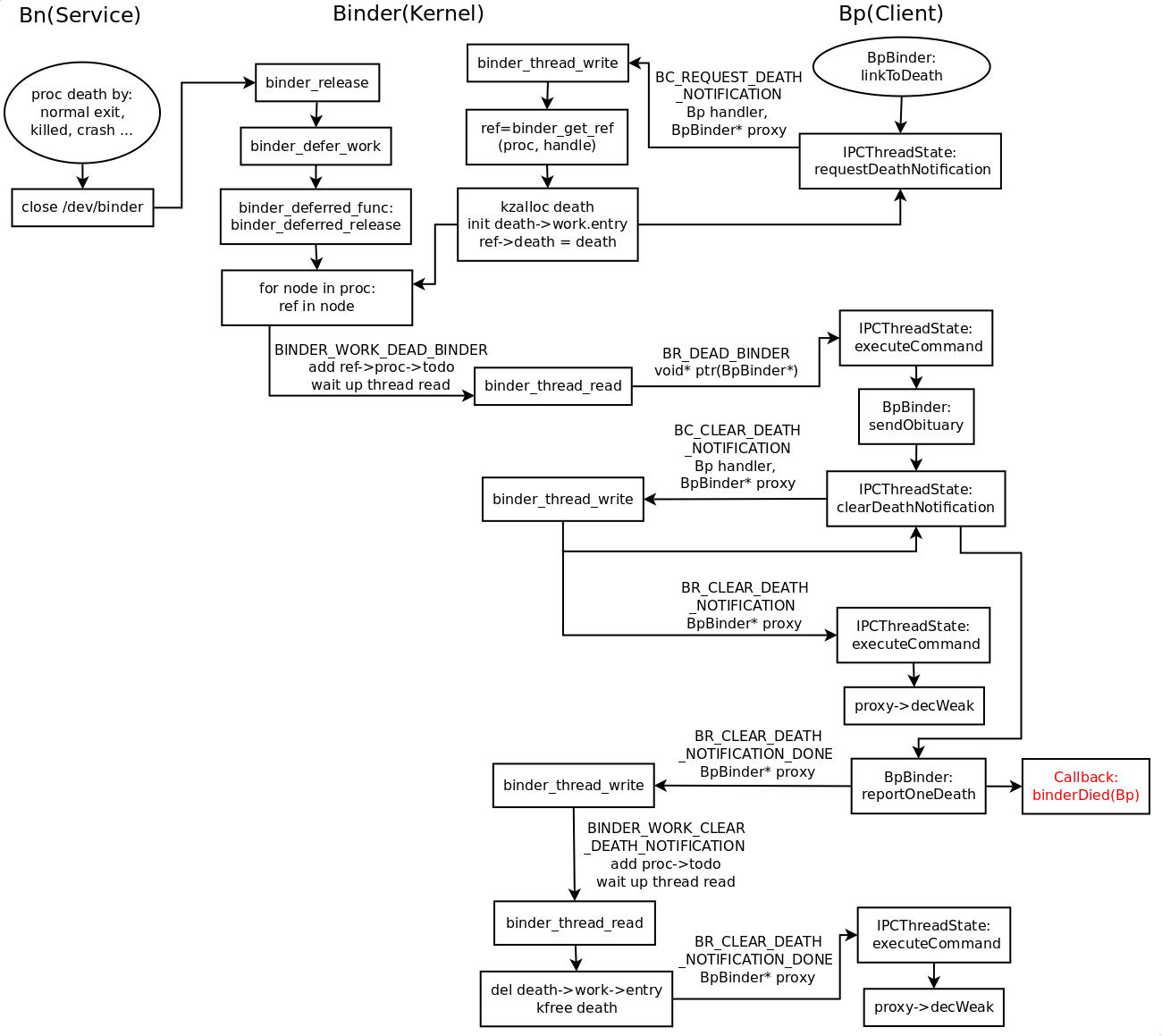
但是这里还有一个疑问。根据前面的分析,最后能触发调用注册的死亡通知回调,最开始是因为 Bn 的 binder 驱动关闭函数(binder_release)里面设置的延迟工作队列触发的。我们很清楚 ProcessState 的构造函数里有明确的 open 过 binder 驱动,但是好像没哪里 close 过。是的,没错,我 grep 了代码好久,确实没哪里 close 过。
于是我就猜测是不是在程序结束后会自动关闭打开过的设备驱动。我询问我们那弄 kernel 的同事,他说应该不会的。然后我做了个小试验,我弄了 native 的服务,跑在命令行下面。不管我是 ctrl + C 发信号量退出,还是写个 client 发个命令让它正常退出,还是直接 kill -9 强制终止,binder_release 都会调用(我有在 kernel 的 binder 驱动里面加打印)。我刚开始怀疑是不是注册了一些信号量函数,然后在收到一个些信号量里面做写什么处理。但是又去翻了好久,没找到相关的代码。
后来没办法,我就专门写了个小程序:
1 2 3 4 5 6 7 8 9
| int main(int argc, char** argv) { int fd = open("/dev/binder", O_RDWR); return 0; }
|
通过 dmesg 的 kernel 打印,发现这个程序退出后,binder_release 依然调用了。后面去度娘查了下,好像 kernel 从哪个版本开始加入了文件设备的计数引用支持。难道又是啥引用计数自动检测到这个打开的文件描述符没人用了,然后就自动关闭啦。后面又拿这个现象去问了下搞 kernel 的同事,他说有可能在文件系统级别有支持。不过这个就比较复杂了。
哎,没办法了,这里我们只能简单的理解为:当打开了 binder 设备的程序,停止运行后(不管是正常退出,还是异常结束)会自动关闭打开过的 binder 设备。然后由 binder_release 设置的延迟工作队列就会触发上面一系列的处理,最终调用到注册的死亡通知回调函数。
java 层接口
前面从 native 层接口,说到 kernel 怎么触发死亡通知。现在我们来看下 java 层的接口是怎么样的。其实从原理篇就应该能看得出,java 层只不过套着 jni 调用 native 层 binder 的接口而已。这里先看看 java 层 binder 的接口:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54
| public interface IBinder { ... .... public interface DeathRecipient { public void binderDied(); } public void linkToDeath(DeathRecipient recipient, int flags) throws RemoteException; public boolean unlinkToDeath(DeathRecipient recipient, int flags); }
|
总体来看和 native 的几乎是一样的。那个 DeathRecipient 的 interface 就是少了自己的对象的参数而已(这个参数 native 层的不要也没关系,反正是自己)。然后我们再来看看 java 层 binder 的实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37
| public class Binder implements IBinder { ... ... public void linkToDeath(DeathRecipient recipient, int flags) { } public boolean unlinkToDeath(DeathRecipient recipient, int flags) { return true; } ... ... } final class BinderProxy implements IBinder { ... ... public native void linkToDeath(DeathRecipient recipient, int flags) throws RemoteException; public native boolean unlinkToDeath(DeathRecipient recipient, int flags); ... ... }
|
java 的 Bn 的接口实现是空函数(和 native 一样,不予以实现),Bp 直接去调 jni,我们去看下 jni:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38
| static void android_os_BinderProxy_linkToDeath(JNIEnv* env, jobject obj, jobject recipient, jint flags) { if (recipient == NULL) { jniThrowNullPointerException(env, NULL); return; } IBinder* target = (IBinder*) env->GetIntField(obj, gBinderProxyOffsets.mObject); if (target == NULL) { ALOGW("Binder has been finalized when calling linkToDeath() with recip=%p)\n", recipient); assert(false); } LOGDEATH("linkToDeath: binder=%p recipient=%p\n", target, recipient); if (!target->localBinder()) { DeathRecipientList* list = (DeathRecipientList*) env->GetIntField(obj, gBinderProxyOffsets.mOrgue); sp<JavaDeathRecipient> jdr = new JavaDeathRecipient(env, recipient, list); status_t err = target->linkToDeath(jdr, NULL, flags); if (err != NO_ERROR) { jdr->clearReference(); signalExceptionForError(env, obj, err, true ); } } }
|
那个列表我们不去管他,主要看下 JavaDeathRecipient 这个对象(那个 gBinderProxyOffsets 保存了 java 层 BinderProxy 的一些类信息的,完了的回去看下原理篇的 java 层那里):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65
| class JavaDeathRecipient : public IBinder::DeathRecipient { public: JavaDeathRecipient(JNIEnv* env, jobject object, const sp<DeathRecipientList>& list) : mVM(jnienv_to_javavm(env)), mObject(env->NewGlobalRef(object)), mObjectWeak(NULL), mList(list) { LOGDEATH("Adding JDR %p to DRL %p", this, list.get()); list->add(this); android_atomic_inc(&gNumDeathRefs); incRefsCreated(env); } void binderDied(const wp<IBinder>& who) { LOGDEATH("Receiving binderDied() on JavaDeathRecipient %p\n", this); if (mObject != NULL) { JNIEnv* env = javavm_to_jnienv(mVM); env->CallStaticVoidMethod(gBinderProxyOffsets.mClass, gBinderProxyOffsets.mSendDeathNotice, mObject); jthrowable excep = env->ExceptionOccurred(); if (excep) { report_exception(env, excep, "*** Uncaught exception returned from death notification!"); } mObjectWeak = env->NewWeakGlobalRef(mObject); env->DeleteGlobalRef(mObject); mObject = NULL; } } ... ... protected: virtual ~JavaDeathRecipient() { android_atomic_dec(&gNumDeathRefs); JNIEnv* env = javavm_to_jnienv(mVM); if (mObject != NULL) { env->DeleteGlobalRef(mObject); } else { env->DeleteWeakGlobalRef(mObjectWeak); } } private: JavaVM* const mVM; jobject mObject; jweak mObjectWeak; wp<DeathRecipientList> mList; };
|
咋再去复习下 gBinderProxyOffsets 获取的那几个 java 类的函数方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
| static int int_register_android_os_BinderProxy(JNIEnv* env) { jclass clazz; clazz = env->FindClass("java/lang/Error"); LOG_FATAL_IF(clazz == NULL, "Unable to find class java.lang.Error"); gErrorOffsets.mClass = (jclass) env->NewGlobalRef(clazz); clazz = env->FindClass(kBinderProxyPathName); LOG_FATAL_IF(clazz == NULL, "Unable to find class android.os.BinderProxy"); gBinderProxyOffsets.mClass = (jclass) env->NewGlobalRef(clazz); gBinderProxyOffsets.mConstructor = env->GetMethodID(clazz, "<init>", "()V"); assert(gBinderProxyOffsets.mConstructor); gBinderProxyOffsets.mSendDeathNotice = env->GetStaticMethodID(clazz, "sendDeathNotice", "(Landroid/os/IBinder$DeathRecipient;)V"); assert(gBinderProxyOffsets.mSendDeathNotice); ... ... return AndroidRuntime::registerNativeMethods( env, kBinderProxyPathName, gBinderProxyMethods, NELEM(gBinderProxyMethods)); }
|
然后我们去看下 BinderProxy 的 sendDeathNotice:
1 2 3 4 5 6 7 8 9 10 11 12 13
| private static final void sendDeathNotice(DeathRecipient recipient) { if (false) Log.v("JavaBinder", "sendDeathNotice to " + recipient); try { recipient.binderDied(); } catch (RuntimeException exc) { Log.w("BinderNative", "Uncaught exception from death notification", exc); } }
|
所以说 java 层其实还是要靠 native 框架运作才行,然后 jni 里面把 native 对象和 java 对象倒腾一下,相互调用一下。
然后 java 层要使用的话,直接调用 java 层 IBinder 的 linkToDeath 接口注册自己的监听对象就行了。不过回想一下前面普通对象传递篇中,ServiceConnection 接口中有一个函数是:
public void onServiceDisconnected(ComponentName name);
没错,这个就是绑定了普通服务的 Bp 端的死亡通知函数。通过这个函数,我们可以指定我们绑定的远程服务已经挂了。不过我们并没调用 linkToDeath 接口啊。这个一猜就知道是系统帮我们调用了。
我们回想下普通对象传递篇。bindService 后,如果服务启动了,就会调用 LoadedApk 里面的一个内部类的 ServiceDispatcher 的 doConnected 函数,进程调用 ServiceConnection 接口的 onServiceConnected 通知我们普通已经连接上了。现在我们再来看看
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55
| public void doConnected(ComponentName name, IBinder service) { ServiceDispatcher.ConnectionInfo old; ServiceDispatcher.ConnectionInfo info; synchronized (this) { if (mForgotten) { return; } old = mActiveConnections.get(name); if (old != null && old.binder == service) { return; } if (service != null) { mDied = false; info = new ConnectionInfo(); info.binder = service; info.deathMonitor = new DeathMonitor(name, service); try { service.linkToDeath(info.deathMonitor, 0); mActiveConnections.put(name, info); } catch (RemoteException e) { mActiveConnections.remove(name); return; } } else { mActiveConnections.remove(name); } if (old != null) { old.binder.unlinkToDeath(old.deathMonitor, 0); } } if (old != null) { mConnection.onServiceDisconnected(name); } if (service != null) { mConnection.onServiceConnected(name, service); } }
|
系统的处理是,当服务一连接上,在触发的 onServiceConnected 的函数里面,帮我们调用了 linkToDeath,自动注册死亡通知函数。不过好像还绕了几下,我继续跟进去看下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
| private final class DeathMonitor implements IBinder.DeathRecipient { DeathMonitor(ComponentName name, IBinder service) { mName = name; mService = service; } public void binderDied() { death(mName, mService); } final ComponentName mName; final IBinder mService; }
|
那个 death 是 ServiceDispatcher 的一个方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
| public void death(ComponentName name, IBinder service) { ServiceDispatcher.ConnectionInfo old; synchronized (this) { mDied = true; old = mActiveConnections.remove(name); if (old == null || old.binder != service) { return; } old.binder.unlinkToDeath(old.deathMonitor, 0); } if (mActivityThread != null) { mActivityThread.post(new RunConnection(name, service, 1)); } else { doDeath(name, service); } }
|
最后如果有跑 activity 线程的 Handler 就发到 Handler 里面去处理,如果没有的话,就直接调用 doDeath:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
| public void doDeath(ComponentName name, IBinder service) { mConnection.onServiceDisconnected(name); } private final class RunConnection implements Runnable { RunConnection(ComponentName name, IBinder service, int command) { mName = name; mService = service; mCommand = command; } public void run() { if (mCommand == 0) { doConnected(mName, mService); } else if (mCommand == 1) { doDeath(mName, mService); } } final ComponentName mName; final IBinder mService; final int mCommand; }
|
所以对普通应用来说,android 给你层层封装好了,什么时候服务准备好了,告诉你可以使用 IPC 进行通信了,什么时候服务挂了,你要么重新启动服务,要么做别的处理。
特殊的 SM
最后,再说一个特殊的列子。还记得前面系统传递 binder 对象篇中说 SM 是很特殊的一个和程序么。它用到了 binder,但是却没有使用 binder 库的那一套框架,而已自己直接写通信程序(为此它把 kernel 里面的一堆数据结构扣了出来)。对了,这里又是 SM 玩非主流。它注册的死亡通知回调和普通又不太一样。
SM 怎么个不一样法,让我们先来看看它注册的是什么东西:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53
| int do_add_service(struct binder_state *bs, uint16_t *s, unsigned len, void *ptr, unsigned uid, int allow_isolated) { struct svcinfo *si; if (!ptr || (len == 0) || (len > 127)) return -1; if (!svc_can_register(uid, s)) { ALOGE("add_service('%s',%p) uid=%d - PERMISSION DENIED\n", str8(s), ptr, uid); return -1; } si = find_svc(s, len); if (si) { if (si->ptr) { ALOGE("add_service('%s',%p) uid=%d - ALREADY REGISTERED, OVERRIDE\n", str8(s), ptr, uid); svcinfo_death(bs, si); } si->ptr = ptr; } else { si = malloc(sizeof(*si) + (len + 1) * sizeof(uint16_t)); if (!si) { ALOGE("add_service('%s',%p) uid=%d - OUT OF MEMORY\n", str8(s), ptr, uid); return -1; } si->ptr = ptr; si->len = len; memcpy(si->name, s, (len + 1) * sizeof(uint16_t)); si->name[len] = '\0'; si->death.func = svcinfo_death; si->death.ptr = si; si->allow_isolated = allow_isolated; si->next = svclist; svclist = si; } binder_acquire(bs, ptr); binder_link_to_death(bs, ptr, &si->death); return 0; }
|
原来每当一个 SS 向 SM 注册的时候,SM 都会为这个 SS 注册一个死亡通知回调。我们来看看这个 binder_link_to_death:
1 2 3 4 5 6 7 8 9 10 11 12
| void binder_link_to_death(struct binder_state *bs, void *ptr, struct binder_death *death) { uint32_t cmd[3]; cmd[0] = BC_REQUEST_DEATH_NOTIFICATION; cmd[1] = (uint32_t) ptr; cmd[2] = (uint32_t) death; binder_write(bs, cmd, sizeof(cmd)); }
|
还记得前面说 kernel 那个保存用户空间传过来的那个地址的时候,为什么要原封不动的保存,然后再原封不动的传回去了不。因为这个指针有2套东西,普通的 IPCThreadState 发下去的是 Bp 对象的指针,而 SM 发下去的是自己的一个 binder_death 结构体的指针。标准不一样,你让人家底下驱动也没办法处理,所以只要原封不动的,发回注册的人自己处理。
我们来看这个 binder_death 里面有什么东西:
1 2 3 4 5 6 7 8 9
| struct binder_death { void (*func)(struct binder_state *bs, void *ptr); void *ptr; };
|
然后我们前面 SM 处理 SS 那里,这个函数指针被指向了一个叫 svcinfo_death 的函数,然后 ptr 是把 svcinfo 这个 SM 保存 SS 信息的数据结构保存了起来。我们看下 svcinfo_death:
1 2 3 4 5 6 7 8 9 10 11 12
| void svcinfo_death(struct binder_state *bs, void *ptr) { struct svcinfo *si = ptr; ALOGI("service '%s' died\n", str8(si->name)); if (si->ptr) { binder_release(bs, si->ptr); si->ptr = 0; } }
|
这个函数没什么特别要说的,就是打印一条信息,然后释放下资源。前面说了 SM 是自己写 binder 通信的,我们来看看它收到 kernel 发送过来的死亡消息的时候怎么处理的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35
| int binder_parse(struct binder_state *bs, struct binder_io *bio, uint32_t *ptr, uint32_t size, binder_handler func) { int r = 1; uint32_t *end = ptr + (size / 4); while (ptr < end) { uint32_t cmd = *ptr++; #if TRACE fprintf(stderr,"%s:\n", cmd_name(cmd)); #endif switch(cmd) { ... ... case BR_DEAD_BINDER: { struct binder_death *death = (void*) *ptr++; death->func(bs, death->ptr); break; } ... ... default: ALOGE("parse: OOPS %d\n", cmd); return -1; } } return r; }
|
看到这个处理,我感觉 binder_death 这个结构完全没必要定义,那个函数是固定的,所以真正传递是那个 svcinfo 的指针,所以发 BC_REQUEST_DEATH_NOTIFICATION 这个命令的第二参数直接写 svcinfo 的指针就行了。然后死亡通知函数固定调 svcinfo_death 就行。难不成以后还有不同的 SS 死亡通知函数不同不成。
总结
android binder 这套框架还是包括了很多东西的,android 也帮我们处理了很多东西。要提供一套高效、易用、可靠的跨进程通信机制还是要处理不少东西。怪不得我以前的头头说 MiniGUI 的多进程版就是一个 demo 而已,离真正使用还很远。现在我才能体会到。